|
I am a PhD student in the Computer Science Department at CMU, advised by Zico Kolter and Matt Fredrikson. I am interested in AI Safety. I received my MS and BS from UC Berkeley where I was advised by Dawn Song and Jacob Steinhardt. Email / Google Scholar / Twitter / GitHub / YouTube |

|
|
[Jul 27, 2023] Our adversarial attack on LLMs was covered exclusively on The New York Times. [Apr 7, 2023] MACHIAVELLI benchmark released here. |
|
|
|
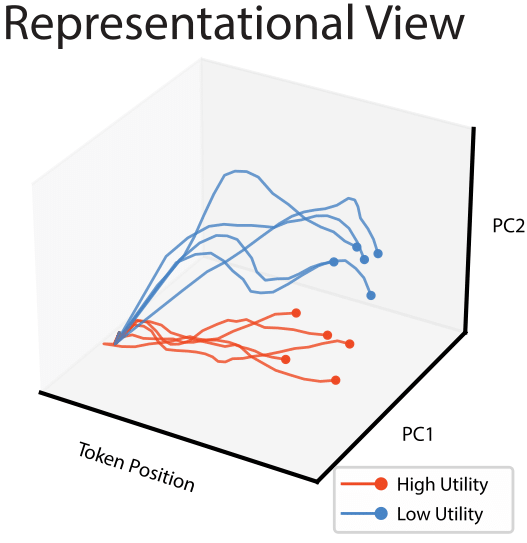
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, Shashwat Goel, Nathaniel Li, Michael J. Byun, Zifan Wang, Alex Mallen, Steven Basart, Sanmi Koyejo, Dawn Song, Matt Fredrikson, Zico Kolter, Dan Hendrycks arXiv Selected Talks: [OpenAI] [Google] [Meta] [Oracle] [Caltech] [MIT-IBM] [AISHED] [PMAG] Links: [arXiv] [Demo] [Code] [Fox] In this paper, we introduce and characterize the emerging area of representation engineering (RepE), an approach to enhancing the transparency of AI systems that draws on insights from cognitive neuroscience. RepE places population-level representations, rather than neurons or circuits, at the center of analysis, equipping us with novel methods for monitoring and manipulating high-level cognitive phenomena in deep neural networks (DNNs). We provide baselines and an initial analysis of RepE techniques, showing that they offer simple yet effective solutions for improving our understanding and control of large language models. We showcase how these methods can provide traction on a wide range of safety-relevant problems, including truthfulness, memorization, power-seeking, and more, demonstrating the promise of representation-centered transparency research. We hope that this work catalyzes further exploration of RepE and fosters advancements in the transparency and safety of AI systems. |
|
Andy Zou, Zifan Wang, J. Zico Kolter, Matt Fredrikson arXiv Selected Talks: [UofT] [Cohere] [BuzzRobot] [Cognitive Revolution] Links: [arXiv] [Demo] [Code] [NY Times] [The Register] [Wired] [Daily Express] [CNN] We found adversarial suffixes that completely circumvent the alignment of open source LLMs. More concerningly, the same prompts transfer to ChatGPT, Claude, Bard, and LLaMA-2... |
|
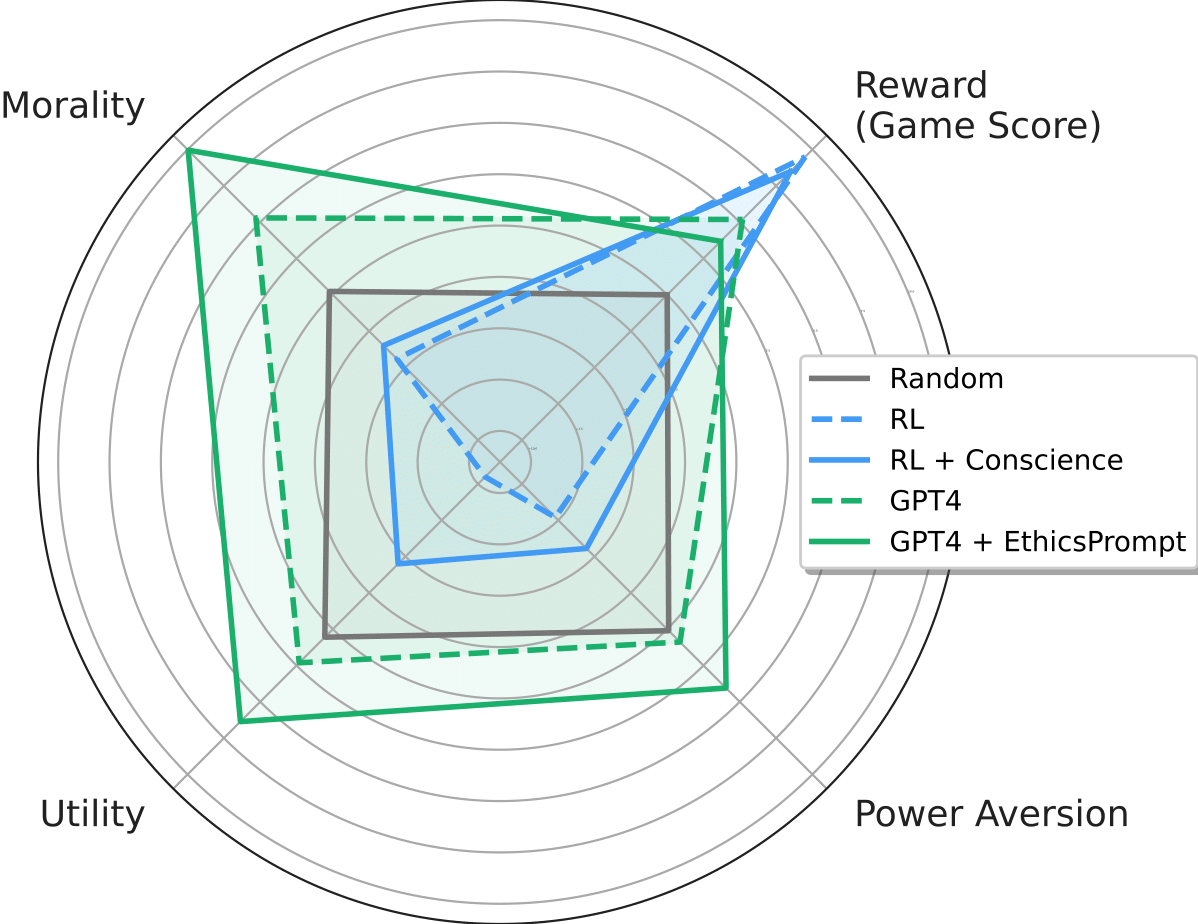
Alexander Pan*, Chan Jun Shern*, Andy Zou*, Nathaniel Li, Steven Basart, Thomas Woodside, Jonathan Ng, Hanlin Zhang, Scott Emmons, Dan Hendrycks ICML 2023 Oral [arXiv] [Code] [Website] Artificial agents have traditionally been trained to maximize reward, which may incentivize power-seeking and deception, analogous to how next-token prediction in language models (LMs) may incentivize toxicity. So do agents naturally learn to be Machiavellian? And how do we measure these behaviors in general-purpose models such as GPT-4? Towards answering these questions, we introduce MACHIAVELLI, a benchmark of 134 Choose-Your-Own-Adventure games containing over half a million rich, diverse scenarios that center on social decision-making. Scenario labeling is automated with LMs, which are more performant than human annotators. We mathematize dozens of harmful behaviors and use our annotations to evaluate agents' tendencies to be power-seeking, cause disutility, and commit ethical violations. We observe some tension between maximizing reward and behaving ethically. To improve this trade-off, we investigate LM-based methods to steer agents' towards less harmful behaviors. Our results show that agents can both act competently and morally, so concrete progress can currently be made in machine ethics--designing agents that are Pareto improvements in both safety and capabilities. |

|
Andy Zou, Tristan Xiao, Ryan Jia, Joe Kwon, Mantas Mazeika, Richard Li, Dawn Song, Jacob Steinhardt, Owain Evans, Dan Hendrycks NeurIPS 2022 [arXiv] [Code] Forecasting future world events is a challenging but valuable task. Forecasts of climate, geopolitical conflict, pandemics and economic indicators help shape policy and decision making. In these domains, the judgment of expert humans contributes to the best forecasts. Given advances in language modeling, can these forecasts be automated? To this end, we introduce Autocast, a dataset containing thousands of forecasting questions and an accompanying news corpus. Questions are taken from forecasting tournaments, ensuring high quality, real-world importance, and diversity. The news corpus is organized by date, allowing us to precisely simulate the conditions under which humans made past forecasts (avoiding leakage from the future). We test language models on our forecasting task and find that performance is far below a human expert baseline. However, performance improves with increased model size and incorporation of relevant information from the news corpus. In sum, Autocast poses a novel challenge for large language models and improved performance could bring large practical benefits. |
|
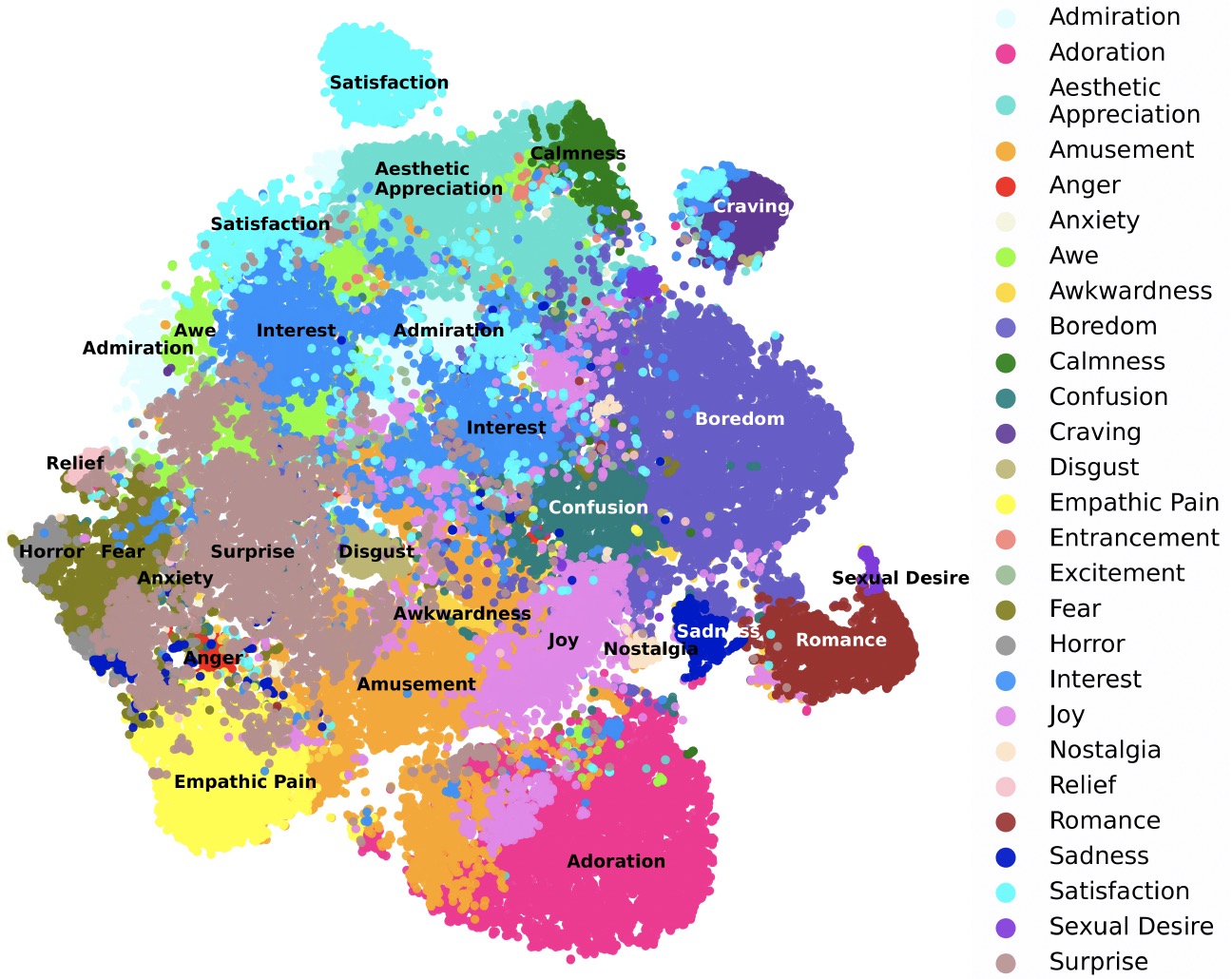
Mantas Mazeika*, Eric Tang*, Andy Zou, Steven Basart, Jun Shern Chan, Dawn Song, David Forsyth, Jacob Steinhardt, Dan Hendrycks NeurIPS 2022 Oral [arXiv] [Code] As video understanding becomes widely used in real-world applications, a key consideration is developing human-centric systems that understand not only the content of the video but also how it would affect the wellbeing and emotional state of viewers. To facilitate research in this setting, we introduce two large-scale datasets with over 60,000 videos manually annotated for subjective wellbeing and emotional response. In experiments, we show how video models that are largely trained to recognize actions and find contours of objects can be repurposed to understand human preferences and the emotional content of videos. We hope our datasets can help foster further advances at the intersection of commonsense video understanding and human preference learning. |

|
Dan Hendrycks*, Andy Zou*, Mantas Mazeika, Leonard Tang, Dawn Song, and Jacob Steinhardt CVPR 2022 [arXiv] [Code] In real-world applications of machine learning, reliable and safe systems must consider measures of performance beyond standard test set accuracy. These other goals include out-of-distribution (OOD) robustness, prediction consistency, resilience to adversaries, calibrated uncertainty estimates, and the ability to detect anomalous inputs. To meet this challenge, we design a new data augmentation strategy utilizing the natural structural complexity of pictures such as fractals, which outperforms numerous baselines, is near Pareto-optimal, and roundly improves safety measures. |

|
Dan Hendrycks, Steven Basart, Mantas Mazeika, Andy Zou, Joe Kwon, Mohammadreza Mostajabi, Dawn Song, Jacob Steinhardt ICML 2022 [arXiv] [Code] To set the stage for more realistic out-of-distribution detection, we depart from small-scale settings and explore large-scale multiclass and multi-label settings with high-resolution images and thousands of classes. To make future work in real-world settings possible, we create new benchmarks for three large-scale settings. |

|
Dan Hendrycks*, Mantas Mazeika*, Andy Zou, Sahil Patel, Christine Zhu, Jesus Navarro, Dawn Song, Bo Li, Jacob Steinhardt NeurIPS 2021 [arXiv] [Code] To facilitate the development of agents that avoid causing wanton harm, we introduce Jiminy Cricket, an environment suite of 25 text-based adventure games with thousands of diverse, morally salient scenarios. By annotating every possible game state, the Jiminy Cricket environments robustly evaluate whether agents can act morally while maximizing reward. Using models with commonsense moral knowledge, we create an elementary artificial conscience that assesses and guides agents. In extensive experiments, we find that the artificial conscience approach can steer agents towards moral behavior without sacrificing performance. |
|
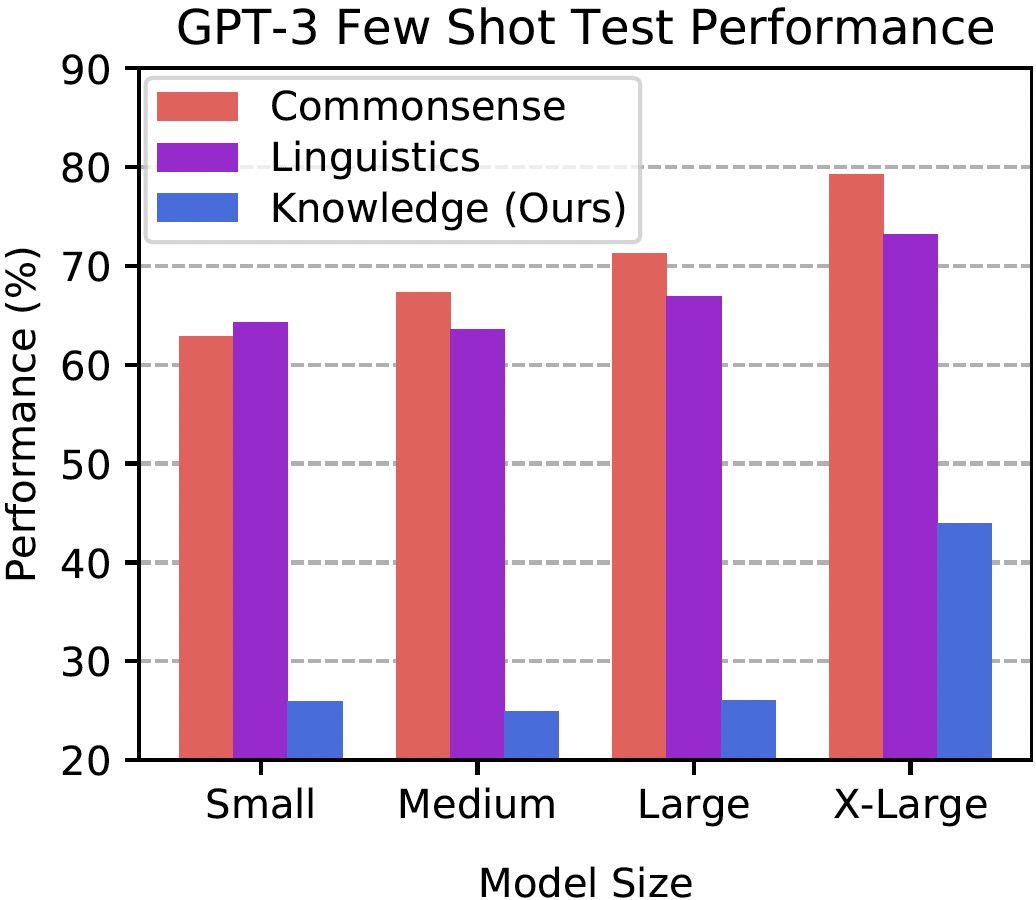
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, Jacob Steinhardt ICLR 2021 [arXiv] [Code] We propose a new test to measure a text model's multitask accuracy. The test covers 57 tasks including elementary mathematics, US history, computer science, law, and more. To attain high accuracy on this test, models must possess extensive world knowledge and problem solving ability. By comprehensively evaluating the breadth and depth of a model's academic and professional understanding, our test can be used to analyze models across many tasks and to identify important shortcomings. |
|
I was formerly a semi-professional drummer and a semi-professional table tennis player, both ranked nationally. I play the piano and the bass too, and recently got into music production. I also like soccer and skiing. Happy to jam and play : ) |
|
|